"Time is an illusion" - Albert Einstein
If you’ve ever built a software system (be it a small website or a highly scalable distributed data store), you probably have dealt with time. Time as a concept is a very fascinating topic to me, be it in physics or distributed systems. In this post, we dive deeper into why time as we know it has been unreliable for most distributed systems and how systems running at scale tackle it. We’ll start by discussing order, physical time, synchronization, historical anomalies and then understand other types of clocks.
What is order and why should we care about it?
Distributed systems basically is scaling out operations that can be done on a single computer to multiple computers. If you did your computations on a single threaded computer, ordering will not matter to you as the order of computation is guaranteed. The problem is compounded manifold when you do the same operation with 100 servers/computers expecting certain eventA to happen before eventB in a repeatable fashion. All financial systems and distributed datastores rely very critically on ordering guarantees. Ordering is the simplest way to ascertain “correctness” of your infrastructure because you can ignore the operations and replicate the same computations if you ran it on a single computer.
The natural state of a distributed system is a partial order i.e there is a local ordering guarantee but the network or the nodes do not make any guarantees on the relative ordering of events. Although, what we instead want in a distributed system is a total ordering guarantee, which means you can essentially guarantee ordering of events relative to each other. This is essentially a hard problem because communication over the network to maintain this over the number the servers is expensive and time synchronization is fragile.
Why is time synchronization fragile?
When dealing with a system we can imagine different scenarios, regarding time:
- We have access to a perfectly accurate global clock
- We have access to an imperfect local clock
- We don’t have access to any clock
The first scenario simplifies operations a lot by giving us total ordering but is based on the assumption that time progresses monotonically and communication to the local clock is inexpensive. The second scenario is closer to the real world where we can have total ordering locally by timestamps but can’t guarantee a global ordering structure. The third scenario removes the notion of real time and instead relies on something called “logical time”, which we will explore later in this post.
Do we have a perfect global clock?
Timestamps (Physical Clock Time) are the go-to tool to preserve ordering information for events in majority of backend systems but it has its fair share of vulnerability stitched into it. In most places, people rely on UTC timestamps for various purposes - from storing user sessions to finding causal relationships between events from logs. But how is this timestamp synchronized across all the servers and why should you care about its downsides?
Most operating systems use a service called the “Network Time Protocol” (NTP) - it periodically checks the computer/server’s time against a reference clock over the internet knows as Stratum 0, which is typically a celsium clock or a Global Positioning System(GPS) which receives time from satellites. NTP also takes into account variable factors like how long the NTP server takes to reply, or the speed of the network between you and the server when setting a to-the-second or better time on the computer/server you’re using. This synchronization protocol has been the bedrock of the majority of the backend systems. Since UTC timezone’s timestamp is a reliable consistent yardstick to other local timezones, a lot of people have used this as a de-facto clock parameter in software systems for decades now. One of the reasons for this is - intuition, simplicity and bias.
While clocks as we know it, works perfectly fine in our day to day lives to track time, it has had its fair share of problems in the past with software systems.
"Almost every time we have a leap second, we find something," Linux's creator, Linus Torvalds, tells Wired. "It's really annoying, because it's a classic case of code that is basically never run, and thus not tested by users under their normal conditions."
Have you ever had a watch that ran slow or fast, and you’d correct its time based off on another clock? Computers have that same problem and you might have already faced outages from your favorite websites and open source software systems because of this.
Soon after the advent of ticking clocks, scientists observed that the time told by even the most accurate clocks on the planet - atomic clocks, and the time told by the Earth’s position were rarely the same. These fluctuations in Earth’s rotational speed meant that the clocks used by global timekeeping services, occasionally had to be adjusted slightly to bring them in line with “solar time”. This keeps us from drifting away to a place where sunsets happen in the morning (Don’t get me started on daylight savings phenomenon that I recently got used to). There have been 24 such adjustments, called “leap seconds,” since they were introduced in 1972. Their effect on people has been profound over the years since everything and everybody started relying on technology in some shape or form.
Whenever a leap second is added, NTP autocorrects all kernel/posix clocks. As recently as 2016 when the last leap second was added in NTP reliant clocks at the time of writing this blog, systems went down globally - here’s Cloudflare status page report of the incident. In 2012, StumbleUpon, Yelp, FourSquare, LinkedIn, Cassandra databases and Tomcat servers went down because of the failure to acknowledge the addition of the extra second. In the linux kernel, however, hrtimer module made sleeping processes active due to the extra second, locking up the CPU for resources; you can read more about the incident - here and the patch to hrtimer here. Since having well-synchronized time is very critical to very large systems, people have researched mechanisms to handle it in various ways. One such way is “leap smear”, introduced by Google - where the internal NTP server acknowledges the leap second but skews the time by adding milliseconds over the course of the entire day.
While we have only had positive leap seconds added till now (and it took down systems every single time), this trend changed in 2020 because of Earth’s accelerated rotational speed in that year starting conversations around the addition of a negative leap second by the timekeepers. While this sounds benign, do notice that systems globally never encountered a negative leap second before, which could have wider impact than anticipated.
The most prominent time bug that seeped into mainstream pop culture was the “Y2K” bug. While the 80s and the early 90s kids will remember talks about this event, for the uninitiated - the advent of the year 2000 was predicted to be the age of digital blackout. In the 1950s and ’60s, representing years with two digits became the norm. One reason for this was to save space but the problem was, if you only use two digits for year values, you can’t differentiate between dates in different centuries. Softwares were written to treat all dates as though they were in the 20th century. This gives false results when you hit the next century. Eventually, hardware capabilities improved but the systems built on top of this date format remained the same. As more data accumulated, the problem was compounded.
The researchers and engineers predicted this and informed the executives about the massive implications. Systems in air traffic control to nuclear power plants globally relied on digital timestamps based on this format at this point, waiting to malfunction. The total global cost of preparing for Y2K was estimated to be between 300 to 600 billion dollars by Gartner, and 825 billion dollars by Capgemini. The U.S. alone spent over 100 billion dollars. It’s also been calculated that thousands of man-years were devoted to addressing the Y2K bug. So when the time came, no major incident happened and we sailed mostly smoothly into the 2000s. Although, there were some incidents that slipped right through the gaps. Two Nuclear power plants in Japan developed faults that were quickly addressed. The faults were described as minor and nonthreatening. The age of the first baby born in the new millennium in Denmark was registered as 100 and this hilarious incident of a man being charged with $91,250 for bringing the tape of The General’s Daughter back to the video store 100 years late.
NTP reliant clocks are also prone to timestamp hijacking as well which can be used by hackers to manipulate distributed systems that expect total ordering. If a system can be tricked into thinking that the event1 has happened after event2, the consequences can be disastrous.
I think we have seen examples of NTP reliant clocks being not the best tool while building very large-scale distributed systems where having precise, well-synchronised and monotonically increasing timestamps are imperative. The consequences of clock malleability is that servers can be tricked into disagreeing on the ordering of events. This can have disastrous ramifications across your systems if you rely on everyone to agree on the ordering of events. Nevertheless, people have made distributed systems with it where either they have ignored the clock uncertainty or have handled worst case clock drift scenario. The best example for this is Google’s Spanner and their TrueTime API which acknowledges clock drift and slows down to wait out that uncertainty. This is a different approach to the same problem solved by “leap smear”.
While building distributed systems you would want to steer clear on assumptions around time and physical clocks.
Assuming that we cannot achieve accurate clock synchronization - or starting with the goal that our system should not be sensitive to issues with time synchronization, how can we order things?
Leslie Lamport in 1978 started discussion around the basic question of - why do we need physical clocks at all? After all, time is just a number that needs to move monotonically and record order of events. This lead to other types of clocks being incorporated in distributed systems.
What are the other types of clocks?
There are different types of clocks that are used in distributed systems. We will explore mainly -
- Logical clocks or Lamport clocks
- Vector clocks
- Hybrid-logical clocks
Logical clocks
It is basically a clock that increments a counter if it performs something or receives message from some other service. This simple incrementing counter does not give us results that are consistent with causal events. If event a happened before event b then we expect clock(a) < clock(b). To make this work, Lamport/Logical timestamp generation has an extra step. If an event is the sending of a message then the timestamp of that event is sent along with the message.
Here is a diagram below to illustrate this mechanism -
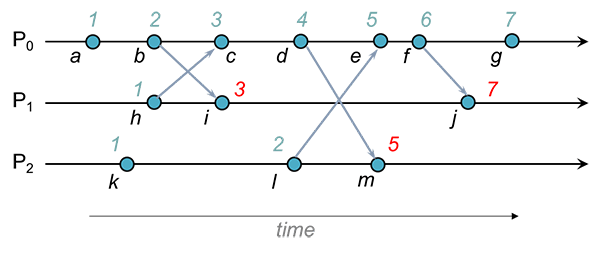
With Lamport timestamps, we’re assured that two causally-related events will have timestamps that reflect the order of events. For example, event h happened before event m in the Lamport causal sense. The chain of causal events is h→c, c→d, and d→m. Since the happened-before relationship is transitive, we know that h→m (h happened before m). Lamport timestamps reflect this. The timestamp for h (1) is less than the timestamp for m (7). However, just by looking at timestamps we cannot conclude that there is a causal happened-before relation. For instance, because the timestamp for k (1) is less than the timestamp for i (3) does not mean that k happened before i. Those events happen to be concurrent but we cannot discern that by looking at Lamport timestamps. We need need to employ a different technique to be able to make that determination. That technique is the use of vector timestamps.
Vector clocks
Vector clocks is an extension that instead of simple counter, uses a vector of counters (one per node). Rather than incrementing a common counter, each node increments its own logical clock in the vector by one on each internal event. Hence the update rules are:
- Whenever a process does work, increment the logical clock value of the node in the vector
- Whenever a process sends a message, include the full vector of logical clocks
-
When a message is received:
- update each element in the vector to be max(local, received)
- increment the logical clock value representing the current node in the vector
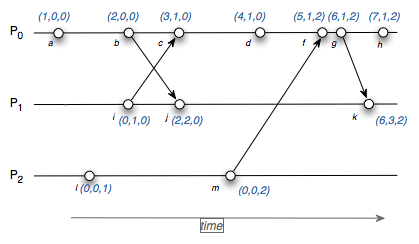
This helps in deriving causal events as well as concurrent events from the vector timestamps. Distributed systems like Dynamo, Cassandra, etc use vector timestamps internally. While it may seem like the perfect solution, you however have to maintain N clocks where N is the number of nodes.
Hybrid logical clocks
HLC was designed to provide causality detection while maintaining the clock value close to the physical clock, so one can use HLC timestamp instead of a physical clock.
Basically, using pretty clever algorithm and clock representation, it achieves
- one-way causality detection,
- fixed space requirement,
- bounded difference from physical time.
HLC is a way to capture causality relationships while maintaining the clock value to be close to the system clock (NTP). Each node has a clock, which have two components the physical component (PT) and a logical component (LT). Each node can also access to its own system time (ST). In plain english, the algorithm for HLC is quite simple. This pair <PT, LT> sits on top of the system clock, and is the HLC.
The algorithm goes like this in layman’s terms -
- When creating a local event, get the system physical time (ST). If system time is greater than PT, then set PT as ST, and reset the LT.
- Otherwise, ST went back in time, or is in the same precision (for example in the same millisecond). Then increment LT by 1.
-
If an event is received with timestamp <msgPT, msgLT>, if ST is greater than both PT and messages PT, then set PT then check ST and do:
- to be ST and reset LT. This means that our ST has advanced.
- if remote messages PT is greater than PT, then set PT = msgPT and LT to be 1 more than msgLT.
- if local PT is greater than remote messages PT, then increment local LT by 1
- else messagePT should be equal to local PT. Set the local LT to be 1 more than max of PT and msgPT.
HLC has very desirable properties like
- Timestamp assigned by HLC is “close to” physical time, ie. |l.e − pt.e| is bounded.
- HLC is backwards compatible with NTP, and fits in the 64 bits NTP timestamp format
- HLC works as a superposition on the NTP protocol (i.e., HLC only reads the physical clocks and does not update them) so HLC can - run alongside applications using NTP without any interference.
- HLC provides masking tolerance to common NTP problems (including nonmonotonous time updates) and can make progress and capture - causality information even when time synchronization has degraded
- HLC is also self-stabilizing fault-tolerant and is resilient to arbitrary corruptions of the clock variables
It is being used in distributed systems like CockroachDB, H-Base, etc.
Parting thoughts
While NTP reliant UTC timestamps come in handy for most of the engineering use cases, as the scale progresses so does the problems with ordering. Being aware of the fickle nature of Physical Time and other types of clocks will always help in alleviating massive rewrites in future. I’ve mentioned the sources and articles for further reading below, hope you understand physical time somewhat better now for your engineering use cases. :)