Inspect Yourself Before You Wreck Yourself
Our live-streaming game engine’s comments system crashed mid-way, with no significant code changes in over a year for the modules that implements the feature.
To shed some context, the engine is built with Elixir/Erlang and MQTT brokers. It leverages all the sweet concurrency and fault-tolerance abstractions Erlang and OTP provides out of the box, so ideally it should never go down; but this was an interesting day in the field.
Uh-Oh!
So what happened? Our clients talk to engine and engine talks back to them with data via MQTT broker - a highly optimised pub-sub broker. Each message type has its own topic. We could see live player count working and increasing, so clearly other supervision trees and features were fine but for some reason comments system was down.
Was our MQTT broker bonking for clients because of load?
We went to our MQTT broker dashboard and checked the load, it was under-utilized. The subscription topics showed up as well in the listeners tab. I manually subscribed to the player count topic from console and received timely message of user count on it. So MQTT is sending messages fine, did the MQTT disconnect happen for all the comments workers?
We checked Observer (a very helpful OTP tool to visualize VM and process data) and found no Comments workers in the set of processes live.
What happened?
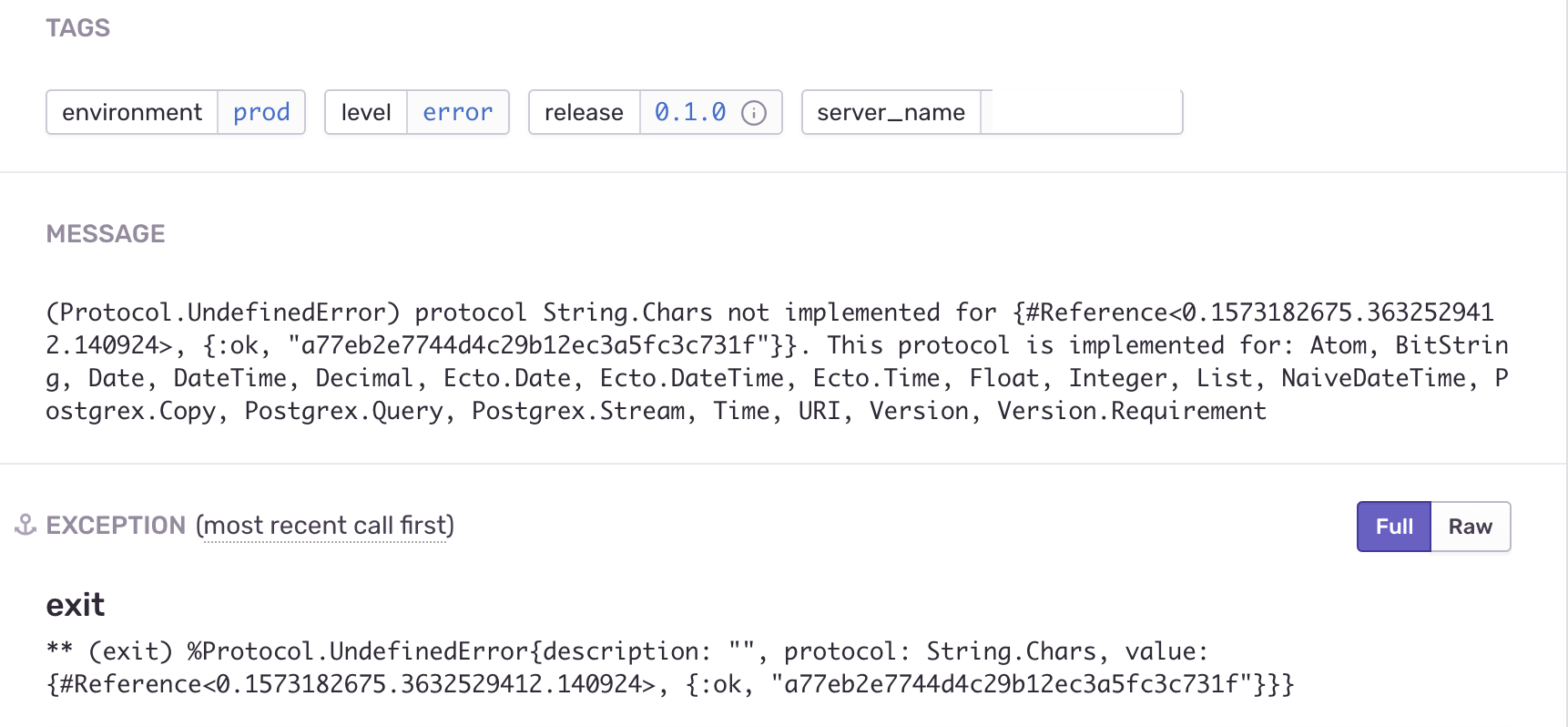
Visit Sentry and we find multiple occurences of this error below in the worker code that moderates and publishes comments.
Huh? We checked the DynamicSupervisor spec, it takes the default configuration.
From HexDocs:
:max_restarts - the maximum number of restarts allowed in a time
frame. Defaults to 3.
So that checks out - the Supervision tree will and should go down after trying to come back up 3 times.
Bug in the system? GIT BLAME!
We follow the line number from Sentry and see this code -
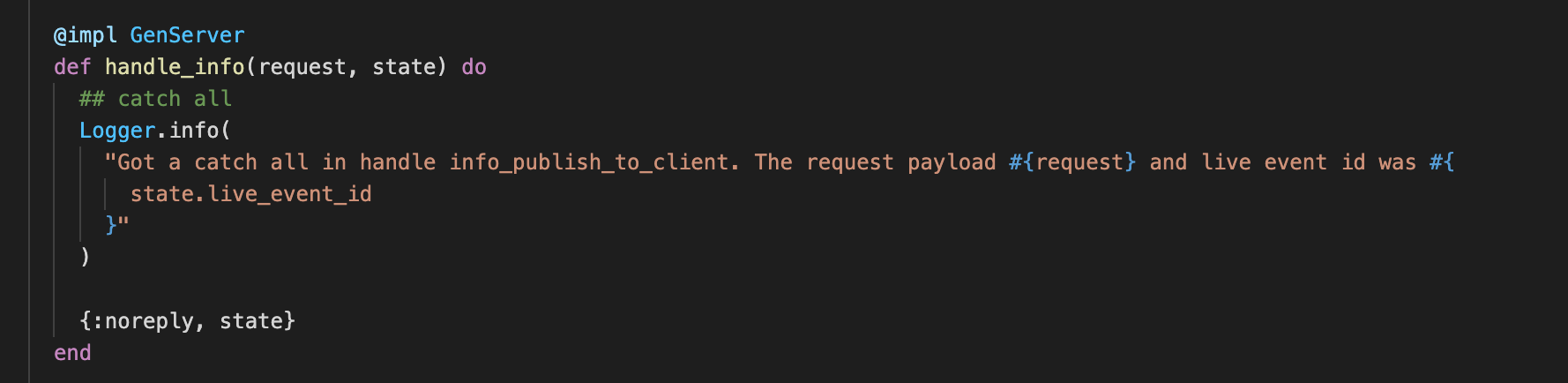
Do you see the bug in this (seemingly-harmless) function? Did you find it?
It’s the statement inside Logger.info.
"#{}" expects the Data structures mentioned in the Sentry error inside the interpolation block. All it needed was #{inspect(request)}
because the Sentry error showed us that it got {#Reference<0.1573182675.3632529412.140924>, {:ok,
"a77eb2e7744d4c29b12ec3a5fc3c731f"}} - a Tuple instead. inspect takes care of casting any ambiguous data types like these and is really helpful in logging.
Wait, but this is a 14 months old code and all the test cases never come here, infact comments system worked fine for all the past events.
As the comment inside the function says, it’s a catch-all for handling unhandled handle_info messages.
The intent was correct (also harmless, because the workers would’ve worked fine without this function), the implementation was not. Either way, it should have never come there randomly for a tuple we don’t know the origin of.
So what kind of messages does handle_info gets?
Besides the synchronous and asynchronous communication
provided by call/3 and cast/2, "regular" messages sent by
functions such as Kernel.send/2, Process.send_after/4 and similar,
can be handled inside the handle_info/2 callback.
Our message publishing was indeed a recursive Process.send_after, but why would it randomly send an unhandled {#Reference<0.1573182675.3632529412.140924>, {:ok,
"a77eb2e7744d4c29b12ec3a5fc3c731f"}} out of no where. That didn’t add up. Rest of the code relied on GenServer.cast, so no where this random tuple could’ve come from.
We checked - its not an UUID or an API-KEY of our eco-system.
Strange?
Digging little further, I found this - closed Github issue in Gun library
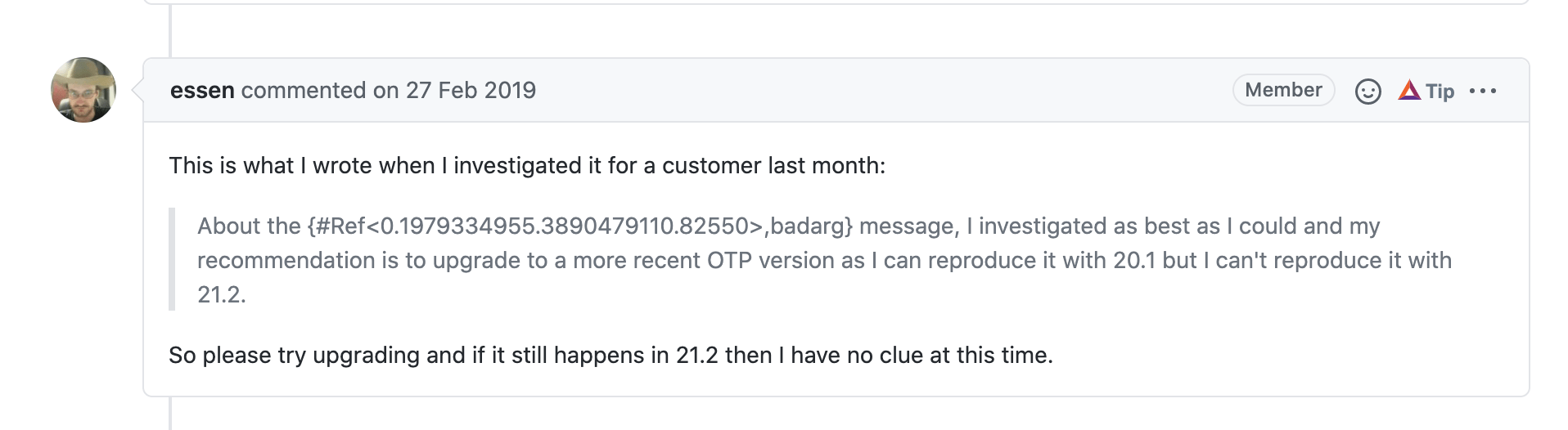
Ah-ha! Someone with the same random tuple pattern in their handle_infos. And we were also on OTP 20.
Gun Library is from NineNines, the people who built Cowboy server. Pretty solid source.
Apparently, it starts happening under high load -
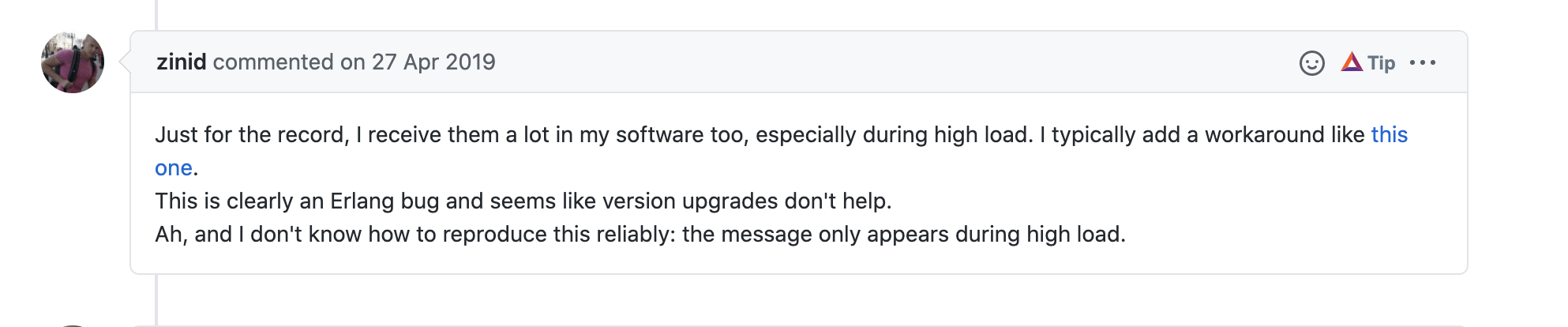
They filed a bug in Erlang for this stray message that gets bubbled up on TCP close - https://bugs.erlang.org/browse/ERL-1049

Our MQTT connections were indeed via TCP protocol from engine to broker.
And it’s fixed in OTP 22.1.1 patch. Yay!
Pro-tip
Always encapsulte your variables with inspect in Elixir while interpolating strings in Logger or sending them as arguments to Sentry.