A Brief History of LLMs
I think it’s a good time for me to recap and put my thoughts on the state of language models. Why? Because now NotebookLM can just make a 10-minute podcast episode out of this which I can revisit! If you’d like to listen to it along with the post, the link’s below:
LLMs in 2024 NotebookLM Audio The audio wanders away from what is being discussed in the post towards the end little bit.
I have been doing ML for some time and the pace of research in LLMs and MLMs has been astonishing to say the least. When I was in undergrad, Deepmind was the only lab outside academia that made news, solving unsolved problems in life-sciences and games. They seemed on track to AGI and were solving incredible problems with AlphaGo, AlphaChess, AlphaFold, etc but with the advent of multiple AGI labs, the progress hasn’t looked this accelerated in a while. I’ll cover some history as I know it, discuss current problems as I see it and future research as I envision it, please DM/email me if I misrepresent or missed out on some work/papers. The point of this blog is to help the uninitiated get a literature/history review and think about how they can meaningfully contribute to the field without getting intimidated.
Machine Intelligence
“Viewed narrowly, there seem to be almost as many definitions of intelligence as there were experts asked to define it.” R. J. Sternberg, The Oxford Companion to the Mind
If your definition of intelligence doesn’t match with Big AI lab’s or some pioneer’s definition, don’t worry you’re in good company. For a primer, Shane Legg and Marcus Hutter covered myriad informal and academic definitions of intelligence back in 2007. They ended up adopting -
“Intelligence measures an agent’s ability to achieve goals in a wide range of environments.” S. Legg and M. Hutter
Later Legg tried to formalize universal intelligence - “an agent’s universal intelligence is a weighted sum of its performance over the space of all environments”.
No lab has tried to approximate their LLM’s performance with this definition. This was also the first time I came across Kolmogorov, you might have heard his name from the recent paper trying to replace transformer MLPs with Kolmogorov-Arnold Networks(KAN).
As you could see, reinforcement learning were (I’d argue still are) the beacon of machine super-intelligence. Deepmind and OpenAI have made significant strides with their agents showcasing superhuman performance in different domains. It started with AlphaZero’s historic win against top Go players to AlphaCoder and AlphaZero’s successor, MuZero. OpenAI also made significant strides with Dactyl. RL systems were learning general-purpose representations and were able to generalize across different tasks. While RLHF is the talk of the town, the next jump in capabilities of LLMs is going to be by leveraging RL for long-horizon tasks, episodic memory and planning. Satinder Singh leads research in discovery and episodic memory at Deepmind, unsure if they are interested in exploring merging their work with language models.
Advent of language models (This is going to be long, treat it like a literature review)
Before LLMs became talk of the town, NLP used to be about statistical models and vector representations. Word2Vec, GloVe were the hot topics. These models were able to capture some of the semantic meaning of words but were severely lacking in context. I remember sentiment analysis, QA and Classification being a hot research topic back then. Tokenization have a longer richer history than language models due to recommendation systems. Anyone remembers spaCy and NLTK?
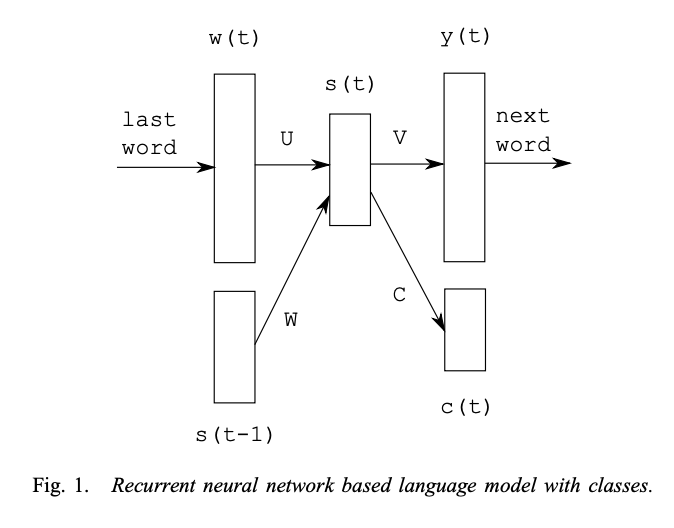
RNNs (LSTMs and GRUs) and CNNs were really good at translation, summarization and sentiment analysis. Even autoregressive generation was a thing back then with RNNLM. A lot of modern language modeling architecture choices have remnants of these models. Back in 2014-2016, Neural Machine Translation performance was kind of a benchmark for testing different architectures on language modeling. Sequence to sequence learning by Ilya Sutskever et al. showed SOTA results in translation tasks with LSTMs. Attention was in fact first introduced in LSTMs as a follow-up work by Bahdanau et al. for neural machine translation. Encoder-Decoder framework was the defacto architecture choice. We still see Encoder-Decoder transformers; among pareto-frontier labs Reka AI uses this architecture and achieved SOTA results in multimodal tasks at the time of its release.
While recurrence is intuitive for sequence data, especially language and time-series, it suffers from problems like properly representing long-term dependencies and exploding/vanishing gradients.. While RNN or their variants makes comeback every now and then, I’m not sure if they are as easy to scale as transformers has been.
In 2017, the original transformers paper by Vaswani et al. which I call the Shazeer architecture, was able to achieve SOTA results in machine translation tasks. The main idea was to move away from recurrence and use multi-headed scaled dot-product attention to represent sequence data. This was very novel at the time because all efforts were around adding attention to recurrence before it. For example, Google’s Neural Machine Translation system Wu et al. used a recurrent attention mechanism to achieve SOTA results. You’d notice overlap of authors between the two papers and beam search being discussed in both papers. The hype around attention is all you need paper is little retrofitted. A following paper called Universal Transformer performed even better on translation quality BLEU scores and LamBADA language modeling tasks where they re-introduced recurrence in transformers. Concurrently, the first idea to improve RNN next-token generation quality with RL and KL-control was proposed in Sequence Tutor. OpenAI also published Proximal Policy Optimization algorithms which is currently the popular RLHF tuning algorithm. OpenAI and Deepmind also did a rare collaboration to release Deep Reinforcement Learning from Human Preferences.
2018 was the year of semi-supervised learning. While it was explored quite a bit before in 2015 in Semi-supervised sequence learning, people were interested in training multi-task language models which could be discriminatively finetuned on narrower tasks now more than ever. The problem at the time was scarce labeled data for pretraining directly on downstream tasks. That year notably, Generating wikipedia by summarizing long sequeunces by Liu et al., ULMFiT, ELmO and the original GPT paper Improving Language Understanding by Generative Pre-Training came out. They all explored pre-training language models on large text corpora and finetuning them for narrower tasks.
That year notably, Generating wikipedia by summarizing long sequeunces by Liu et al. was the first paper that explored decoder-only transformer that could scalably attend to long sequences, much longer than typical encoder-decoder architectures and next-token prediction as universal objective (Shazeer again). Building on top of this architecture, original GPT paper was mainly about adding task-aware input transformations during fine-tuning to achieve effective transfer learning and it was the first paper in generative modeling which used Byte Pair Encoding (BPE) for tokenization.
If you’re impressed by GPT4o voice mode now, you should revisit duplex which Google demo’ed back in 2018. The voice assistant was able to talk to humans and take actions. But as usual they couldn’t execute or double down on the product or the research.
In 2019, Google and Shazeer doubled down on multi-task objective with encoder-decoder transformers while OpenAI’s Ilya and Radford were exploring decoder-only transformers. T5 and GPT2 were released couple of weeks apart as far as I remember. T5 was trained with massive dataset of 7TB with 11 billion parameters and employed both masked and autoregressive objectives. While GPT2 was trained with only 40GB of web data and 1.5 billion parameters conditioned on a document plus questions format. While T5 was massively useful for academia and industry due to its versatility, GPT2 showed real promise because it could not only generalize across different domains it could also fabricate coherent stories which was a big deal. If you are annoyed by AI doomerism now, GPT2 had a lot of doomerism around its release. OpenAI was apprehensive about releasing it. GPT2 changed the architecture from Liu et al. mainly by moving the layer normalization to the input of each sub-block and using AdamW optimizer. The paper showed direct correlation between zero-shot performance as a function of model size. GPT2 was a major milestone but more importantly everyone who makes the argument that language models are stochastic parrots should revisit the Generalization vs Memorization section of the GPT2 paper. Later that year, OpenAI came out with Sparse Transformers. Tranformers were still difficult to train with hundreds of layers so the paper suggested alternating dense and locally banded sparse attention patterns in the layers of the transformer. Concurrently, Shazeer introduced Multi Query attention in his solo paper where he suggested sharing the keys and values across all of the different attention “heads”, greatly reducing the size of these tensors and hence the memory bandwidth requirements of incremental decoding. Shortly after DialoGPT came out from Microsoft which pretrained GPT2 with reddit conversation data, as far as I know, this was the first attempt at chatGPT in the wild.
In 2020, OpenAI came out with the scaling laws for neural language models which suggested that architectural details such as network width or depth have minimal effects within a wide range (I don’t completely agree with this, I’ll come back to this). Simple equations govern the dependence of overfitting on model/dataset size and the dependence of training speed on model size. The paper had lots of helpful equations. For instance, they presented a handy formula for parameter count which can be further reduced to with the standard so FLOPs per token on forward pass would be . The final scaling law that they proposed was where L is the loss, N is the number of parameters, D is the dataset size, and are the critical parameters where the loss starts diverging and and are scaling constants. Google came out with Meena, a 2.6B parameter neural network trained as multi-turn dialogue model. Shazeer did another solo paper where he introduced the famous SwiGLU and GeGLU activation functions. He had the best ending to a paper I’ve read - “We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.”
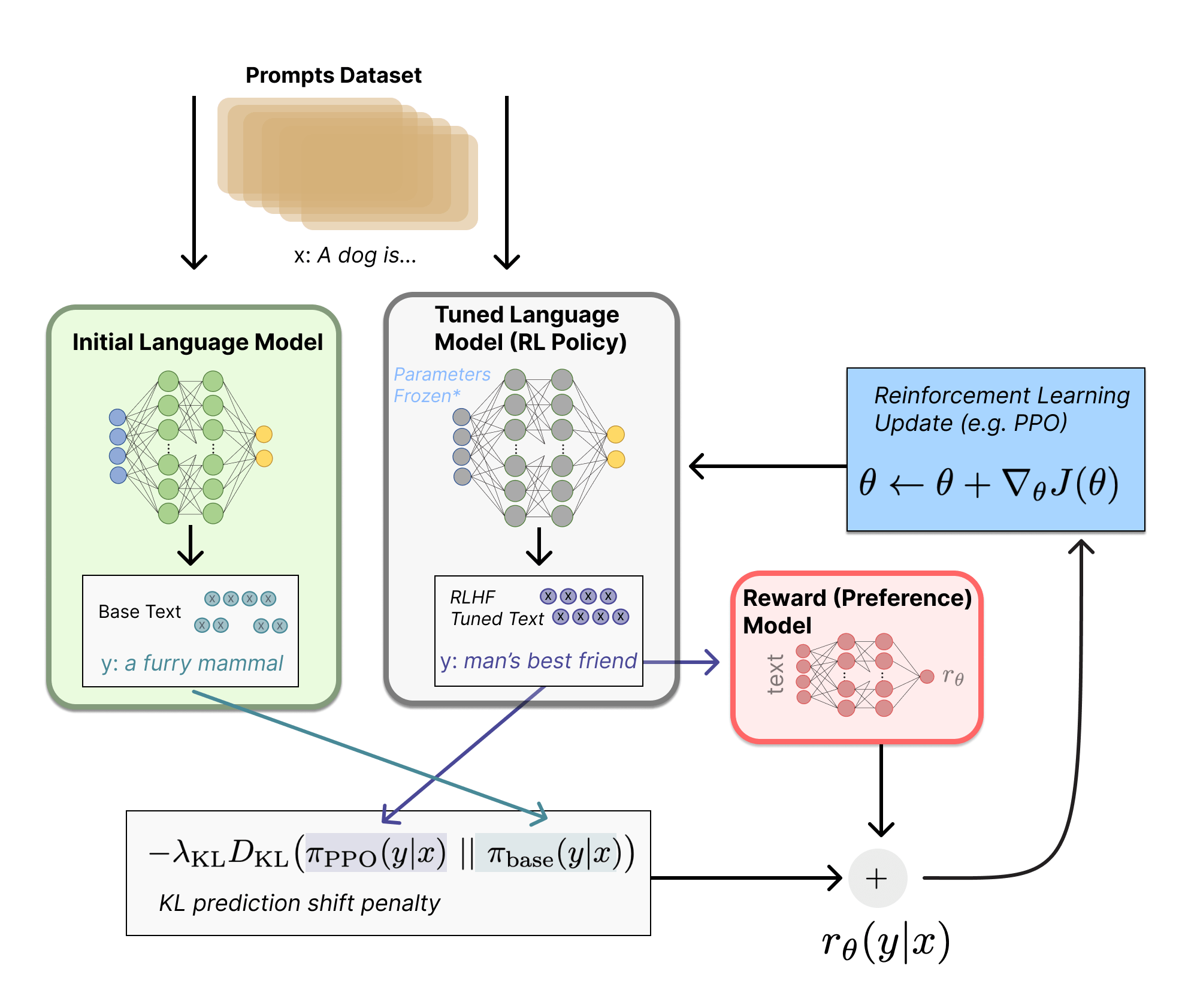 credit: RLHF blog
credit: RLHF blog
But the most seminal work that came out of 2020 was the GPT3 paper from OpenAI and Learning to summarize from human feedback paper. GPT3 was trained with 175B parameters and 300B token dataset consisting mostly of filtered Common Crawl, Expanded WebText along with 2 internet books corpora and English-language Wikipedia. The paper introduced meta-learning and in-context learning phenomena in language modeles in few-shot settings. Architecturally there was not much difference from GPT2 except they used alternating dense and locally banded sparse attention patterns in the layers of the transformer. This showed convergence of architecture tuning and onset of scaling laws. GPT3 didn’t achieve SOTA in a lot of evaluations but was either really close in few-shot settings or surpassed it. Unlike last time, OpenAI didn’t release the weights of their GPT3 models and provided only API/Playground access. OpenAI had major success with learning to summarize from human feedback paper where they used a small GPT3 model of 1.3B/6.7B parameters and RLHF tuned with preference data and PPO to acheive SOTA in summarization tasks far surpassing supervised fine-tuned model’s and reference summaries. Training a language model with reinforcement learning was, for a long time, something that people would have thought as impossible both for engineering and algorithmic reasons. The picture above is from the huggingface’s blog, the method is quite straightforward. One thing to note is the above diagram makes it look like both models generate different responses for the same prompt, but what really happens is that the RL policy generates text, and that text is fed into the initial model to produce its relative probabilities for the KL penalty. This initial model is untouched by gradient updates during training. Some of the interesting tidbits from the papers was, they found T=0 gave them the best outputs and there was scaling laws with reward models as well. Some of the main limitation of RLHF at the time and even now is the expensive forward passes that on top of the training phase. Their 6.7B model finetuning with RLHF took 320 GPU days. Meta on the other hand came out with Retrieval Augmented Generation (RAG) but with seq2seq models and Allen Institute introduced Sliding Window Attention in the Longformer paper to tackler long-context tasks.
In 2021, everyone outside OpenAI doubled down on scaling and beating/reproducing GPT3 while people inside OpenAI got safety pilled. A lot of great people and even founding members from OpenAI left to start Anthropic. A bunch of hackers and engineers with no masters or even PhD degrees were tracking AI progress in discord channels from their homes. Notably at the time, EleutherAI was doing a lot of incredible work in interpretability and language modeling from their discord channel. They released GPT-J, which was the first open reproduction of GPT3 and almost matching the 6.7 GPT3 model built in the open, from scratch and open sourced, the only tradeoff they made was to keep the dense attention layer to keep the training simpler. EleutherAI also released the Pile dataset which it was trained with. Pile was and still is super popular for research. The main author of GPT-J, Ben Wang and collaborator Leo Gao who also worked on Pile, went on to join OpenAI.
Google demo’ed their LaMDA model in Google I/O in 2021. LamDA built on top of Meena and had a lot going for it. It was exclusively pretrained on dialog and conversational data. Architecturally, it used relative attention as described in T5 and gated-GELU activation. They used Google’s AI principles as a benchmark to safety finetune based on human ratings of the responses on them (this was pre-anthropic’s HHH paper). The crowdworkers were explicitly informed to reply in a safe, sensible, specific, interesting, grounded, and informative manner. They discrimitavely finetuned with this prompt structure -””. They also made the model learn to consult a set of external knowledge resources and tools. Deepmind released their first large language model papers with Gopher and RETRO. Gopher was a 280B params trained with relative positional encoding and RMSNorm, instead of layer norm whereas RETRO was the first paper that did retrieval with transformers, but as a joint pretraining objective. Keep in mind, these were only papers and results with no open weights to reproduce to investigate further. Concurrently, OpenAI released their WebGPT paper which was interesting because in the paper when optimizing over the same reward model, rejection sampling triumphed over RL. Albert Gu released State Space Models with S4, it was the first divergence from transformers since 2017 and was trying to get around quadratic runtime of attention and long range dependency problems; I won’t talk a lot about them as I don’t fully understand them and haven’t worked with them; I hear SSM are becoming go-to architecture for audio/video at a lot of places. Anthropic also released their first language model paper where they investigated model caliberation. RoPE was introduced in RoFormer paper which is used in every transformer++ model these days. And LoRA finetuning was published as well, although I’d argue it got popular mainly once they got merged into Huggingface libraries properly.

Soon after in 2022, OpenAI released InstructGPT paper, which became the foundational work for ChatGPT that we know now. The paper followed most of the same work that was done in summarization with human feedback paper, except their findings on “alginment tax” and benign overfitting. They found a simple algorithmic change that minimizes this alignment tax: during RL fine-tuning if you mix in a small fraction of the original data used to train the base model, and train on this data using the normal log likelihood maximization, you can roughly maintain performance on safety and preference. GPT3.5 was also released but there was no paper or technical report. EleutherAI open sourced GPT-NeoX, a 20B model which used RoPE and parallel attention. Deepmind released their Chinchilla paper which refuted some claims in OpenAI’s scaling laws paper. They found results in scaling laws that tokens and parameters linearly increase at a 20:1 ratio. OpenAI and Microsoft introduced µTransfer, where they claimed many optimal HPs remain stable even as model size changes. Later, while Deepmind released Flamingo, a multimodal foundation model built on top of Chinchilla (Flamingo was the first model that used vision encoder on top of frozen langugage model as far as I know), Google released PaLM, a 540B model which took very similar architecture choices to GPT-NeoX with parallel attention and RoPE, the only difference being SwiGLU activation. One of the early instance of synthetic data for training was mentioned in this paper by Meng et al..PaLM and T5 were reused a lot in Google for other models (Flan-T5, Flan-Palm, etc), couple of weeks later Google finetuned PaLM on mathematical dataset and achieved SOTA in MATH and MMLU-STEM benchmarks with Minerva. One of the nifty notes in inference time techniques mentioned in Minerva is “the reason majority voting improves performance is that while there are many ways to answer a question incorrectly, there are typically very few ways to answer correctly”.
I’d remiss to not mention the origin of Chain-Of-Thought, earlier that year the first Chain-of-Thought paper came out and later the self-consistency trick. On the open science front, Tri Dao’sFlashAttention and Tim Dettmers’s 8bit training were milestone papers and origin of PEFT (Parameter efficient Fine-tuning); LoRA, bitsandbytes and FlashAttention democratized ML research and allowed a lot of people finetune their own models on cheaper GPUs. Meta was just starting to get into LLM race. They released their own open reproduction of GPT3 with the family of OPT models which ranged from 125m to 175B parameters. Not only were the range of smaller models helpful for research but most importantly they published their training log-book. This gave some insights of how hard it is to train these large models and have to constantly babysit them or write really good automation around it. I have been in war-rooms when I was scaling backend systems for high traffic, seems like warroom for these large models span multiple days and nights. Around that time, BLOOM came out from BigScience workshop. Such a fun story that is. People from academica, Huggingface and students (and surprisingly lots of involvement of europian orgs) got together and trained the 176B multilingual model.

Around the end of 2022, depsite Deepmind publishing their paper on a helpful, correct, and harmless conversational agent with Sparrow before, ChatGPT was launched for the public in November and instantly blew up and became a milestone in the history of LLMs. I think that’s why its important to either productize research or open source it. BTW Sparrow was I think the first paper which used a form of self-play with LLMs. Meta also releasedGalactica with a lot of controvery around it which made the team take it down but honestly in my opinion was a great model. The paper had lots of cool ideas. They wrapped citations with [START_REF] [END_REF] tokens and wrapped step-by-step reasoning with a working memory token <work> token. I think this was the first model that did this in the open, which is now a very common technique. Claude uses a very similar $$thinking$$ token to wrap step-by-step reasoning. I think if Meta’s PR around the release was better, the model would have been much more popular. Anthropic published their Constitutional AI paper which put RLAIF(Reinforcement Learning from AI*(+Human)* Feedback) on the forefront. Remember the Meena paper from earlier where Google’s consitituion was directly given to the workers who were generating the preferences? well, in this case they created a reward model that took human preferences and AI generated preferences based on the constitution they set.

BTW even though RLHF/RLAIF was all the talk, noone was open sourcing their reward models. Follow Nathan Lambert to keep up to date on RLHF.
2023 saw accelerated progress in LLMs and VLMs (Vision Language Models). Meta, Anthropic, MosaicML and Microsoft stepped up their game. Meta released their paper on Toolformer, which taught language models to use tools like calculator or search engine. Later they released their first LLama models, this was a big deal because you could quantize the model and run all kinds of inference and experiments on a model that almost matched GPT3 on some benchmarks. On the same day, Microsoft published paper on their multimodal model Kosmos-1, which showed multimodal models built on top of LLMs perform better on reasoning tasks than their counterparts. Soon after, Claude-1 was launched, marking the entry of Anthropic in the AI Assistant market. OpenAI launched GPT4 in March, although they finished their training 2023. GPT4 saw a huge jump from GPT3 and since it was all closed research, it left everyone speculating. The main takeaway was that they could accurately predict performance from small models and their scaling laws. Microsoft published LLava, which has become the go-to model to finetune on top of visual tasks in research. They leveraged GPT4 to get visual instruction data of images, kept the vision encoder frozen while finetuning the LLM weights and the projection layer. Anthropic and NYU published Pretraining Language Models with Human Preferences. The paper moved the onus of good data to pretraining phase, they suggest Pretraining with human feedback results in much better preference satisfaction than standard LM pretraining followed by finetuning with feedback, i.e., learning andthen unlearning undesirable behavior. Charlie Snell, who’s at Deepmind right now, published ILQL which was a model-based offline RL method to finetune models with human preferences. ILQL is very tractable and can be implemented with the TRL library from Huggingface, not sure why it never took off. EleutherAI came out with suite of Pythia models. They had an interesting claim that training order have minimum effect on memorization and model size and term frequencies have direct correlation with reasoning tasks. In this podcast episode in 2024 by Dwarkesh, Curriculum learning is mentioned; clearly closed labs have some sophisticated setup and insight on training order. MosaicML came out with MPT models which surprisingly great performance in their model size and used AliBi at such scale, it was one of the first models that could do 84k context length and licensed for commercial use unlike Llama, they also released their own training framework LLM foundry which could restart a failed run by it own and could run equally on nvidia and amd chips. Meta came out with LIMA, which started discussion on data quality; they showed that only finetuning with 1000 high quality curated responses can get you a really strong model. At Berkely, Patil et al. published Gorilla which demostrated LLMs capabilities of tooluse more accurately. With Toolformer and Gorilla, tool-use or function-calling became a want from the community, so much so in 2024 function-calling comes out of the released models altogether. Stanford published Direct Preference Optimization(DPO) paper which proposed we can just directly optimize on maximum likelihood on preference data instead of RL algorithms like PPO. It showed real promise and the debates began on DPO vs PPO. Microsoft released their Phi1 models in Textbook is all you need. The paper showed strong correlation between data quality and LM performance. I think it was common knowledge how C4 and common crawl dataset had a lot of garbage in it and needed a lot of quality filtering steps. Phi1 had phenomenal benchmark scores for a 1.3B model. On the open source front, I don’t quite remember the month but in early 2023 GGML was launched by Georgi Gerganov. GGML/GGUF was a remarkable milestone because you can now run your models locally on your macbooks with Ollama and LMStudio because of it. OpenAI after quite some published a detailed paper on RLHF with Let’s verify step by step, where they introduced process-supervised reward models. Till now reward models judged based on outcome of language models, but with the advent of performance boosts with chain-of-thought, this leveraged teaching language models to reward correct step-by-step reasoning. Claude2 came and became SOTA, not only because it was a great assitant but it could process 100K context length. Meta released Llama2, not much difference in architecture to Llama1 except they trained on larger number of tokens, added Grouped Query Attention(GQA) to larger models, and did data quality filtering on SFT stage. Working on top of the findings of Lets verify Step by Step paper, Microsoft published WizardMath which introduced Instruction Reward Models. They achieved SOTA with a 70b Llama2 model and even surpassed ChatGPT on GSM benchmarks, I’d argue they could’ve done even better with a better base model and process superivision data.
 For some reason, EvolMath paper is not discussed much.
For some reason, EvolMath paper is not discussed much.
Adept AI came out with Fuyu-8b, it had a much simpler architecture for a multimodal model. They used a nifty trick to just feed the image patch projections to the first layer of their decoder transformer. Around this time, Deepmind and Google Brain was merged to accelerate Google’s AI efforts. MistralAI was founded and came out with Mistral7b which outperformed Llama2 models or matched bigger models on benchmarks. MistalAI also came out with Mixtral which put MoE on the forefront, but I’m not a huge fan because even though there’s only few active paramters for each prompt, the models need a lot of vram to my liking. Google Deepmindreleased their first Gemini models behind API, they pushed the SOTA MMLU scores and their demo was magical. They eventually received underwhelming reception because of accusations of fake demo and people not able to reproduce the results. But to their credit, they released Fun-Search which is a cool project and bridges Satinder Singh’s line of RL work in discovery with LLMs.
Current State of LLM/VLM
 credits: Hyung Won Chung
credits: Hyung Won Chung
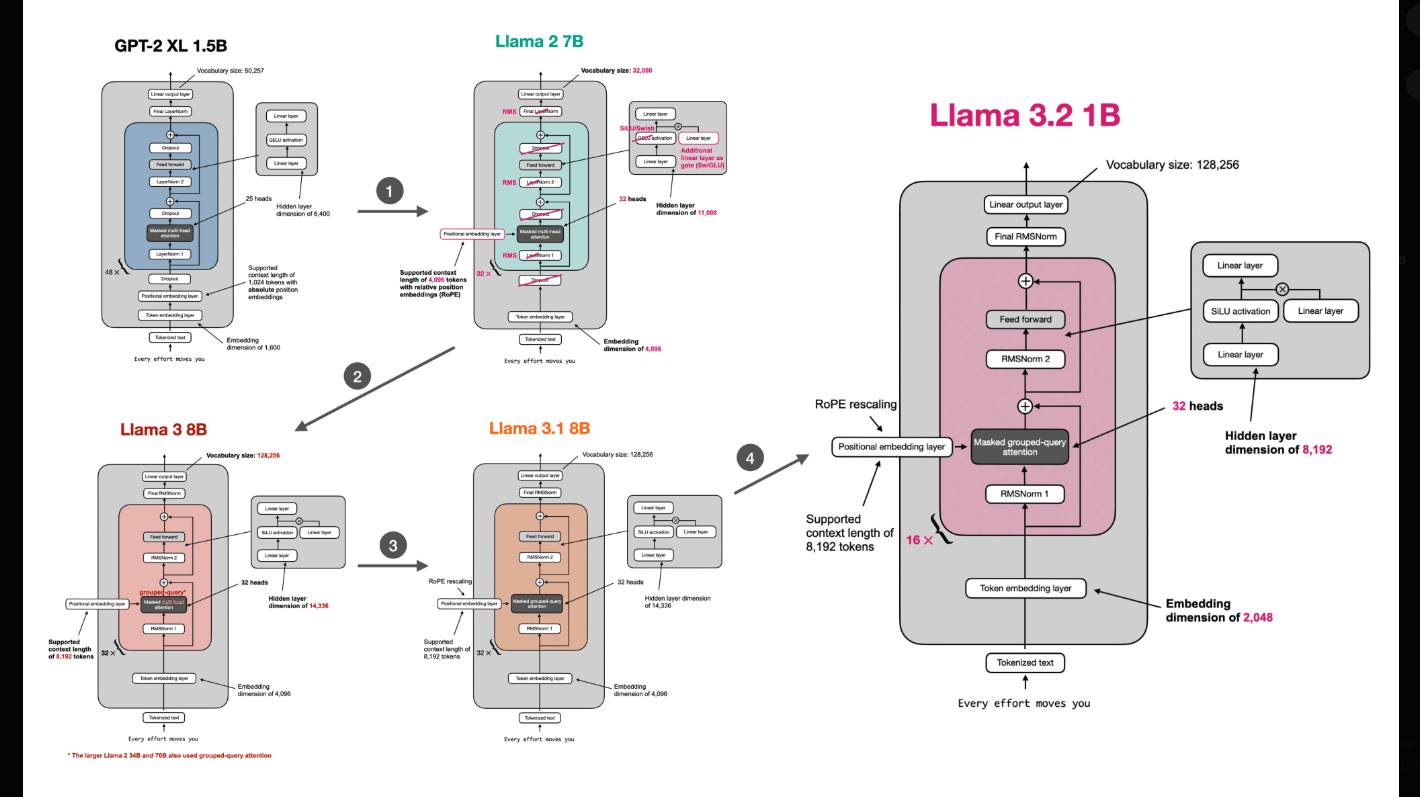 credits: Sebastian Raschka
credits: Sebastian Raschka
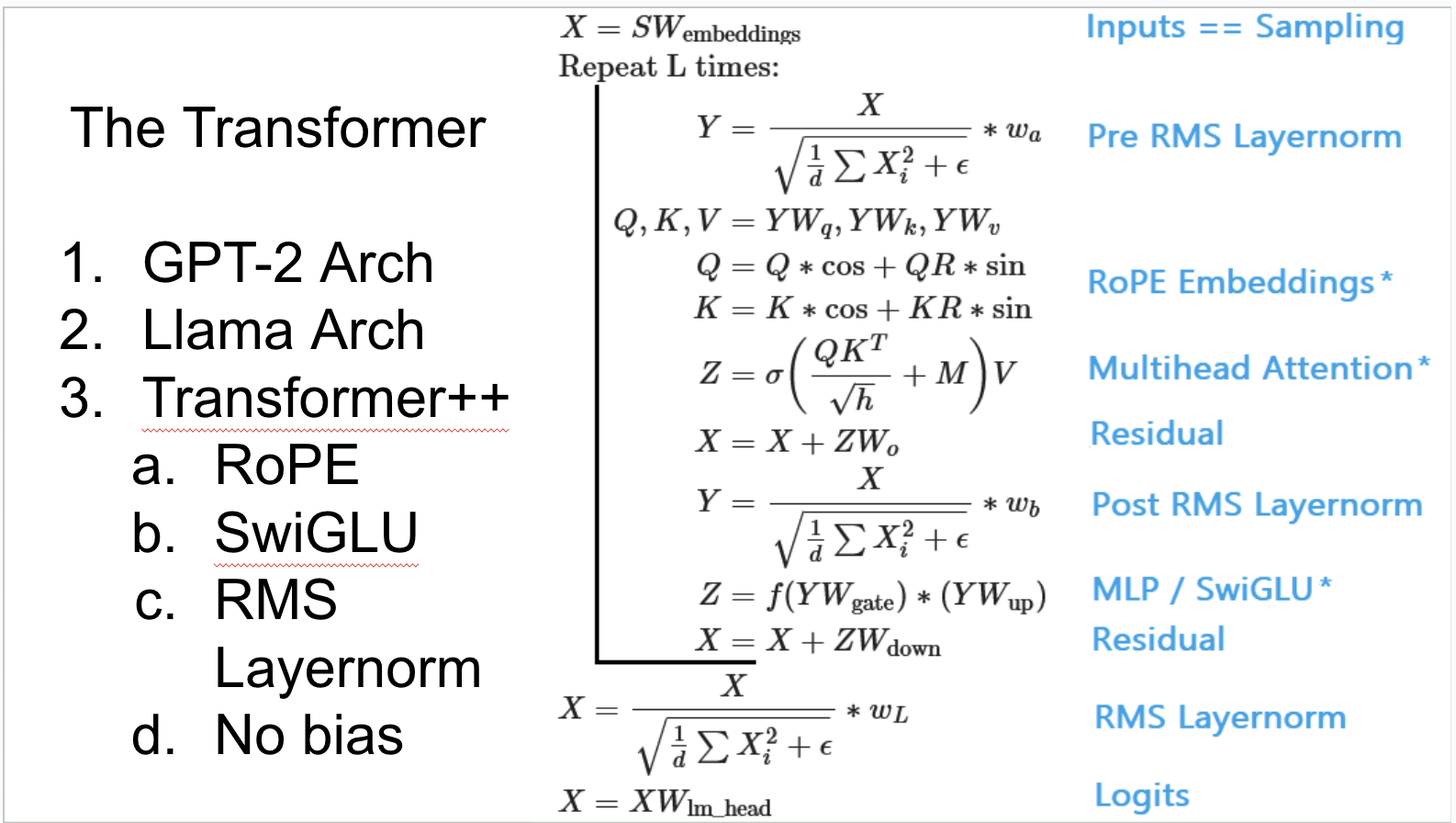 credits: Daniel Han
credits: Daniel Han
Architecture changes in language models have largely converged to certain established patterns, with only minor variations among labs releasing open-source models and those attempting to match closed-source models. As a result, I’ll be focusing less on discussing architecture changes in future conversations about AI development.
Its 2024, and we’re still seeing incredible progress. Most of the SOTA research is closed source but the ones that are open, help us speculate on what might be happening. From China, Qwen was released by Alibaba as their effort towards AGI. Claude3 came out beating Gemini in most benchmarks and 200k context alongwith vision capabilities. Microsoft released their Phi3 models which either matched or beat a lot bigger model’s benchmark scores. They mention leveraging high-quality training data and knowledge transfer techniques to challenge conventional scaling laws. Although they are great, I think they fail my own vibe-check in terms of LLM usage. Meta came out with LLama3, Llama3.1 and Llama3.2 which were the first open weight model that beat Gemini, GPT4/GPT4o and Claude3 in most benchmarks including vision. The only problem with open weights models right now is matching context length and performance of closed source models. For instance, Gemini claims to process 1 million multimodal context length; I have no idea how they did it or how they even got their million token text datasets from. Anthropic launched Claude3.5 Sonnet which took the throne away from Meta. Qwen also released their Qwen2.5 which beats even Llama3.1 405b model in benchmarks but their biggest model have Qwen license which is restrictive as its governed by the laws of China in case of dispute. But the most special paper that came out last year but was presented in ICML 2024 is Physics of language models, everyone should watch this ICML video on it. They ran tons of experiments on small scale to extrapolate model behavior. Some findings I can back up are that for reasoning tasks, depth beats breadth. This goes against what OpenAI said earlier in their scaling laws paper. Other interesting stuff I found: Beefing up the dataset for a well-known entity helps less common entities perform better too. How you add knowledge matters a lot for downstream tasks - if you don’t do it right, no amount of finetuning will help with knowledge extraction. Most internet pretraining data is junk, but if you throw in domain-specific stuff, language models can figure out what’s higher quality on their own. On the open source front, this was the year for AllenInstitute. They open sourced everything about their models, from dataset to training recipe to weights. They not only released their first models with Olmo, their recent release of MolMO puts them on top3-5 in leaderboards. This was Apple’s year as well, they released bunch of cool papers like OctopusV2 and FerretUI. Deepmind released published on Alphaproof and Alphageometry, where they claim their model achieved same level as silver medalist in IMO.
Recently, OpenAI’s o1 models have gotten a lot of attention. They beat all the models in reasoning tasks and its available to public unlike deepmind’s Alphaproof model. The major breakthrough of o1 model is that it takes time to find the right chain of thought, which I can only speculate builds on top of Let’s verify step by step technique and EvolMath.
Parting thoughts
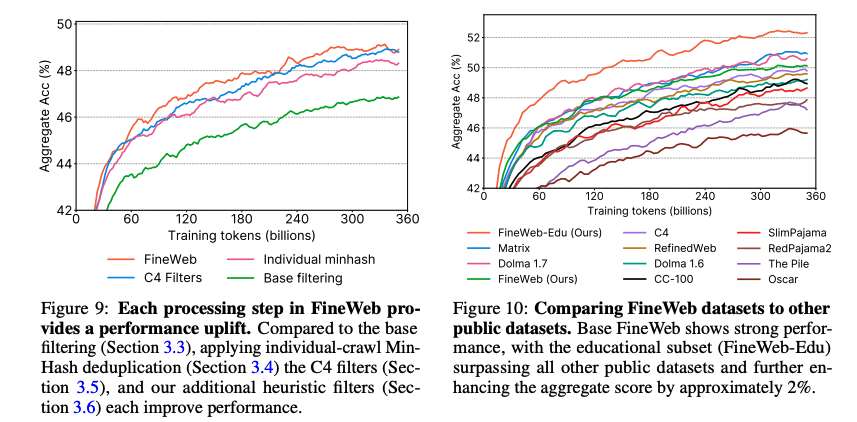
As you’d notice, a lot of evaluation benchmarks are saturated at this point and since it’s all closed research, there’s no publication of contamination or leakage percentage. It’s very easy to contaminate a model with popular evaluation benchmarks. As mentioned in Physics of Language models ICML video, one could translate MMLU in French and upload it on the Internet, it’ll be picked up by next C4 release and everyone will have to retrain their models. This is why I think benchmarks are not useful for evaluating models. I’d rather use benchmarks to evaluate my model against SOTA but not for research or evaluation of new ideas. Build your own evaluation set or outsource it to companies like ScaleAI which have built their private evaluation sets. I wouldn’t focus much on architecture techniques, they all have mostly converged. I’d much rather focus time and energy on cleaning and augmenting pretraining data with all the tips and tricks in the bag. Annotate all documents with their respective domains, add more coding+math data in the mixture and some instruction+chain-of-thought data at the very end of pretraining phases. Get the best base model I could get and spend more time on inference time search techniques. If you’re building for the first time, there are plenty of great open source datasets with trillions of tokens like FineWeb from Huggingface (I’d track their progress on this) and Dolma dataset from AllenAI (They keep updating it).
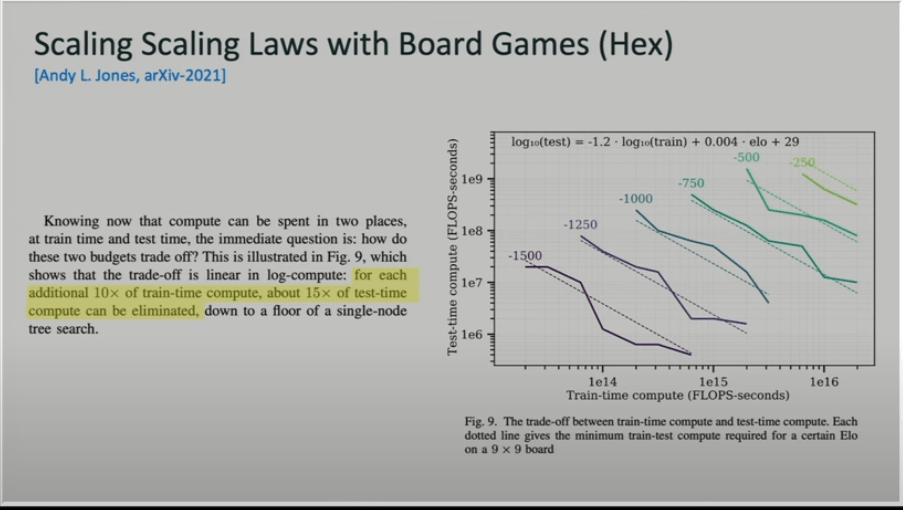 credits: Noam Brown
credits: Noam Brown
I don’t think we have fully explored RLHF and reward models.
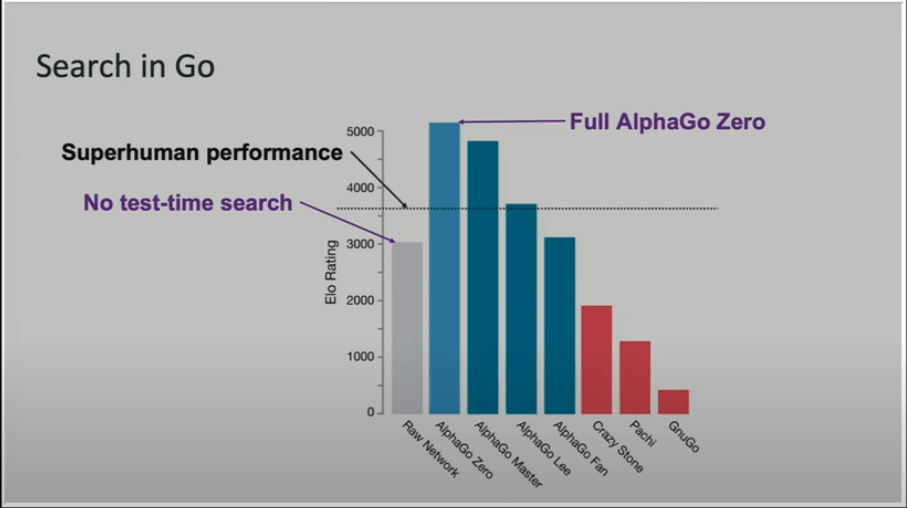 credits: Noam Brown
credits: Noam Brown
I think we’re still in the early days of training models with human preferences. PRM and EvolMath’s techniques need to be explored more. Multi-agent search which tackle different aspect of reasoning with reward models can be used to instill correct model behavior for different tasks. I think decoding research is also under-utilized for reasoning, most of the research in decoding is to get higher throughput.
 credits: Richard Sutton
credits: Richard Sutton
Ultimately, I think we need student-teacher kind of collaborative model technique which could refer to the reasoning model for system-2 thinking/searching, while being able to refer to itself for system-1 tasks for completely solving arc challenge.
While the architecture choices have landed on AdamW being the default optimizer, there are some interesting optimizer research that are worth noting: Distributed Shampoo optimizer, Sophia optimizer from Meta and Ademamix optimizer from Apple. Ademamix is interesting because it retains information for longer period of steps and slows down model forgetting and Sophia is the first scalable second order optimizer at par with Adam. Softmax is a bottleneck, you can imagine on a higher level as an activation function but its remarkably slow, can we do something different? Apple looked into this with Sigmoid self-attention.
I hope there’s some research in tokenization as well. Current form of BPE tokenization adds a lot of room for bugs and is a adjacent block needed for any LLM to be built. If LLMs could learn subword units on its own, it’d solve lot of problems.
I hope you enjoyed reading or listening to this post!
Edited with Claude